DeepSeek vs GPT o1 | Features, Performance, & Pricing
DeepSeek-R1 and OpenAI’s GPT-o1 take different paths in AI reasoning, making their comparison essential. DeepSeek-R1, an open-source model, relies on reinforcement learning-first training, while GPT-o1 follows a structured, step-by-step problem-solving approach within a proprietary system.
Beyond performance, this debate centers on accessibility, efficiency, and real-world usability.
In this breakdown, we’ll examine their core differences - from architecture and performance to accessibility and cost - helping you determine which model best suits your needs.
Key Takeaways
- DeepSeek-R1 is open-source and great for coding and logical tasks
- GPT-o1 is proprietary, supports images, and handles complex reasoning better
- DeepSeek-R1’s MoE improves efficiency, while GPT-o1’s model enhances context
- DeepSeek-R1’s API is far cheaper and best for high-volume AI tasks
What Are DeepSeek-R1 and OpenAI-o1?
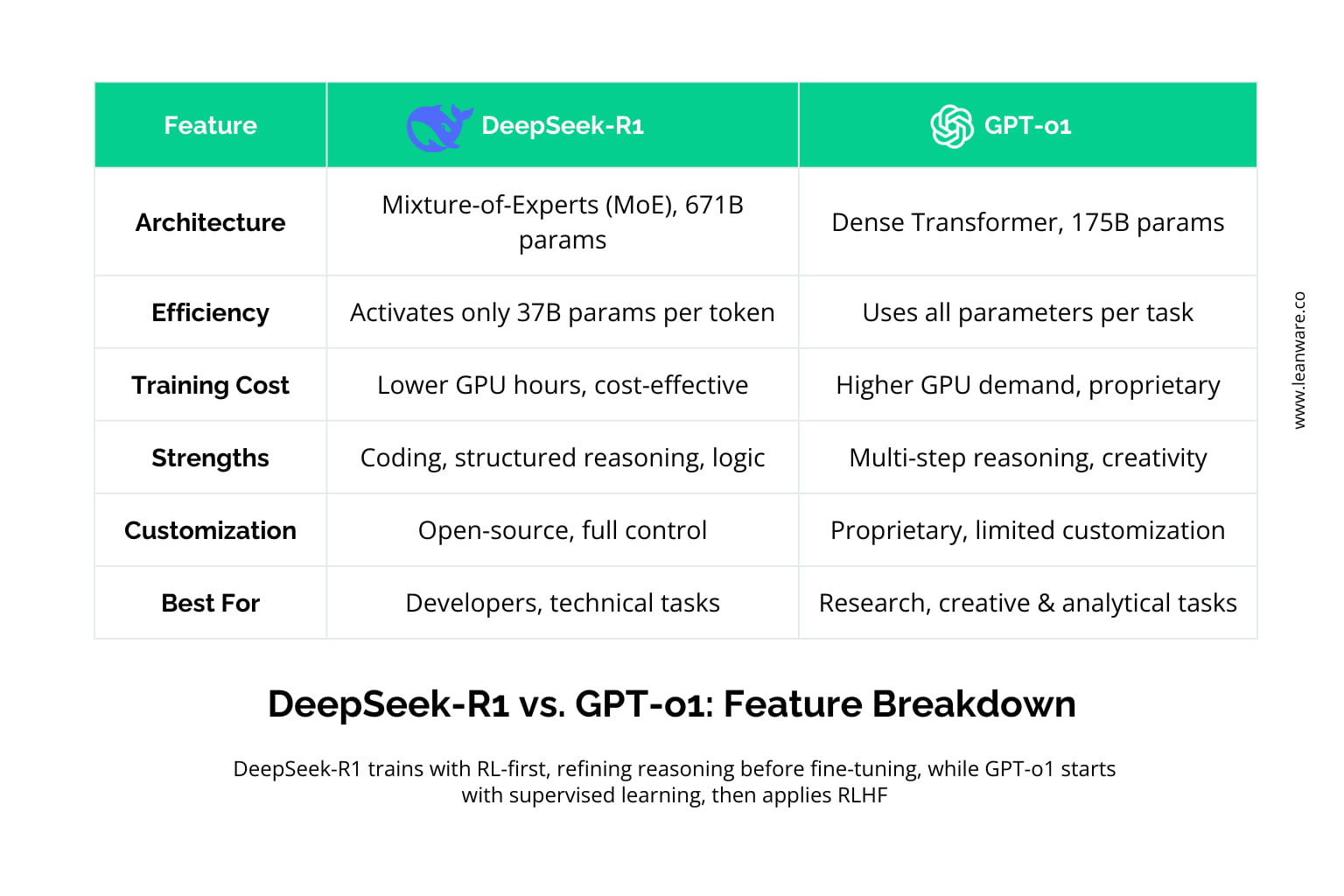
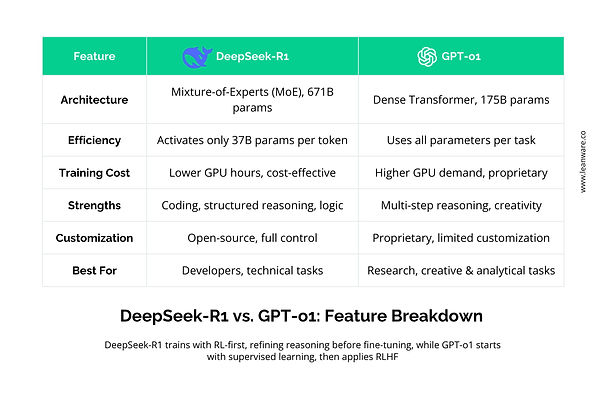
DeepSeek-R1 is an open-source AI model developed by DeepSeek and launched in January 2025. It features a Mixture-of-Experts (MoE) architecture with 671 billion parameters, but only a fraction - 37 billion - are activated per token, optimizing computational efficiency. This design allows it to handle complex tasks like coding, structured problem-solving, and logical reasoning while keeping costs low.
Compared to proprietary models, DeepSeek-R1 requires significantly fewer GPU hours for training, making it a cost-effective choice for developers and organizations looking to deploy AI without heavy infrastructure costs.
OpenAI’s GPT-o1, released in late 2024, takes a different approach. Built on a dense transformer-based architecture with 175 billion parameters, it refines its outputs using chain-of-thought reasoning and reinforcement learning from human feedback (RLHF).
This makes GPT-o1 particularly strong in multi-step reasoning and contextual understanding, positioning it well for applications that require in-depth analysis, creative writing, and complex query handling.
How do these models compare?
Both models offer advanced language processing but differ in design, training methods, and accessibility.
DeepSeek-R1 is cost-effective and open-source, making it ideal for projects with budget constraints, coding automation, and structured problem-solving. Its customization options benefit those who prefer community-driven development.
GPT-o1 is proprietary and optimized for general-purpose reasoning, making it better suited for complex problem-solving in scientific, engineering, and enterprise applications where reliability and vendor support matter.
So, it comes down to flexibility and affordability versus structured enterprise features and refined reasoning.
DeepSeek R1: Key Features and Capabilities
DeepSeek-R1 is built for efficiency, affordability, and adaptability, which makes it best for structured AI applications.
- MoE Architecture activates only part of its 671B parameters, improving efficiency and reducing compute costs.
- Cost-efficient with API pricing at $0.14 per million input tokens.
- 128K context length enables long-form content handling.
- Strong in coding with advanced debugging and automation.
- Open-source, allowing full customization.
GPT-o1: Key Features and Capabilities
GPT-o1 is designed for structured reasoning, multimodal AI, and enterprise-grade applications.
- Chain-of-thought reasoning enhances problem-solving.
- 175B parameters improve contextual understanding.
- Multimodal AI processes text and images.
- A vast knowledge base supports research and customer support.
- Enterprise API ensures easy integration and strong support.
Open-Source vs. Proprietary Approaches
Factor | DeepSeek-R1 (Open-Source) | GPT-o1 (Proprietary) |
Customization | Fully adaptable, self-hosted | Limited, fixed API usage |
Transparency | Open architecture & training data | Black-box model |
Cost | Lower, free for self-hosting | Higher subscription-based |
Support | Community-driven updates | Official updates & support |
Optimization | User fine-tuning possible | Pre-optimized by OpenAI |
Scalability | Self-host or third-party platform | Cloud-based, scalable API |
Capabilities | Text-based, strong in reasoning | Supports text & images |
Performance Benchmarks DeepSeek-R1 vs. GPT-O1
Both models have unique advantages and trade-offs. so the best choice depends on how you plan to use them.
Processing Speed and Accuracy
DeepSeek-R1 processes tasks efficiently, but GPT-o1 is slightly faster. In benchmark tests, GPT-o1 completes tasks in about 77 seconds, while DeepSeek-R1 takes approximately 84 seconds.

The difference is small, but for real-time applications, speed may be a factor.
In terms of accuracy, DeepSeek-R1 performs exceptionally well in structured reasoning, coding, and mathematical tasks. It scores 79.8% on the AIME 2024 benchmark and 97.3% on MATH-500, closely matching GPT-o1-1217 and outperforming other models in logic-based evaluations.
Model | Processing Speed | AIME 2024 Accuracy | MATH-500 Accuracy |
R1 | ~84 sec/task | 79.8% | 97.3% |
o1 | ~77 sec/task | Comparable | Comparable |
Reasoning and Abstract Thinking
DeepSeek-R1 is good in structured reasoning due to its reinforcement learning-first approach. This training method allows it to break down complex problems into step-by-step solutions, which makes it highly effective in coding, logic, and math-based tasks.
GPT-o1, on the other hand, uses chain-of-thought reasoning, which helps it tackle abstract and multi-step problem-solving.
Both models show a strong reasoning ability, GPT-o1 may hold a slight edge in tasks that require deep contextual understanding.
Model | Strengths | Best Use Cases |
R1 | Strong in logic, coding, problem-solving | Programming, automation, technical tasks |
o1 | Better at abstract reasoning | Language modeling, research, analysis |
Multilingual Support
DeepSeek-R1 is an option for developers working primarily in English or Chinese. However, if multilingual support is critical, GPT-o1 has the edge.
Model | Language Support | Multilingual Capability |
DeepSeek-R1 | English, Chinese | Limited beyond primary languages |
GPT-o1 | English and many other | Better multilingual proficiency |
Pricing and Accessibility
DeepSeek-R1 offers free access through its official website and mobile apps, with additional API pricing for developers integrating it into applications.
GPT-o1 requires a subscription for full access, with ChatGPT Plus ($20/month) for general users and ChatGPT Pro ($200/month) for advanced features, including unlimited access to GPT-4o and GPT-o1.
Model | Subscription Cost |
DeepSeek-R1 | Free (with API pricing) |
GPT-o1 | $20/month (ChatGPT Plus) / $200/month (Pro) |
Token Pricing Comparison
DeepSeek-R1’s API pricing is up to 27 times cheaper than GPT-o1, which makes it more viable for high-volume processing and cost-conscious businesses.
Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) |
R1 | $0.14 (Cache Hit) / $0.55 (Cache Miss) | $2.19 |
o1 | $15 | $60 |
API Availability and Usability
DeepSeek-R1 offers an open-source API with a simple setup, compatible with OpenAI SDKs, allowing for full customization in self-hosted environments.
GPT-o1 provides a proprietary API with detailed documentation and support but has higher costs and limited flexibility.
Self-Hosting DeepSeek-R1 vs. Using GPT-o1 via OpenAI
Aspect | DeepSeek-R1 (Self-Hosted) | GPT-o1 (OpenAI-Managed) |
Control | Full control over model and data | Limited, vendor-managed |
Cost | Lower long-term operational costs | Higher subscription & API costs |
Customization | Highly flexible | Restricted by OpenAI policies |
Support | Community-driven | Dedicated vendor support |
Ethics, Safety, and Bias
Both models reflect biases from their training data. DeepSeek-R1, as an open-source model, relies on community-driven datasets, which vary in representation. However, despite being open-source, DeepSeek-R1 is still developed under Chinese regulations, meaning it may restrict certain politically sensitive topics, including references to events like Tiananmen Square.
GPT-o1, developed by OpenAI, uses curated datasets and structured bias mitigation strategies. While OpenAI aims to minimize bias, its model also adheres to certain content policies that may restrict or filter specific discussions.
No AI model is entirely free from bias, and both require ongoing evaluation to address potential issues.
For safety, GPT-o1 employs vendor-managed content filtering, reducing the risk of harmful or misleading outputs. DeepSeek-R1 allows developers to customize safety measures, but this places more responsibility on users to ensure appropriate safeguards.
DeepSeek-R1’s open-source nature gives users control over its architecture, but its training data may still reflect regulatory constraints. GPT-o1, as a proprietary model, doesn’t reveal its internal workings but follows structured ethical guidelines.
Wrapping Up
DeepSeek-R1 and GPT-o1 take different approaches to AI - cost-effective customization versus structured, high-performance AI.
If you need flexibility, affordability, and control, DeepSeek-R1’s open-source framework is a better choice. If enterprise-grade support, refined reasoning, and multimodal capabilities matter more, GPT-o1 stands out.
So, benchmarks help, but real-world testing in your environment is the best way to determine which model fits your needs.
FAQs
Why Is DeepSeek-R1 So Good?
DeepSeek-R1 excels due to its efficient training methods and open-source approach. It matches the performance of leading models like OpenAI's o1 in tasks such as mathematics, coding, and reasoning, all achieved at a fraction of the development cost.
What Makes DeepSeek Different?
DeepSeek distinguishes itself by developing high-performing AI models without relying on the most advanced chips. This approach challenges the prevailing dependence on high-end hardware in AI development.
How Is DeepSeek Better?
DeepSeek's R1 model offers comparable performance to leading AI models while being more cost-effective. Its open-source nature allows for widespread use and customization, promoting innovation and accessibility in the AI community.
Who Owns DeepSeek?
DeepSeek is a Chinese artificial intelligence company founded in 2023 by Liang Wenfeng. It is owned and solely funded by the Chinese hedge fund High-Flyer.