AI Pricing Models Decoded: Usage-Based Pricing vs. Seat-Based Pricing for AI Features
AI pricing becomes more complicated when the cost of delivering value is no longer tied directly to the number of users in a product. Traditional SaaS pricing assumes a relatively stable relationship between seats, usage, and cost. AI systems introduce a different dynamic. The same user action can trigger multiple model calls, background processes can run without user involvement, and infrastructure costs can vary significantly across accounts with the same number of seats.
As a result, the pricing model and the underlying cost structure are not always aligned. A company may pay for AI consumption based on tokens, model calls, or compute usage while charging customers a fixed per-seat fee. Understanding that gap is the starting point for choosing the right pricing model.
Let's compare seat-based pricing, usage-based pricing, and hybrid approaches for AI products, examining how each aligns with AI workloads, where each breaks down, and what technical founders and engineering leaders should consider before committing to a pricing structure.
How AI Is Breaking the Seat-Based Pricing Assumption
Seat-based pricing became the SaaS default because it matched how value was created. A CRM seat, a project-management seat, a design-tool seat, each represented a human doing roughly predictable work in a session, and the cost to serve that human was low and stable. Charging per seat aligned price with value cleanly, and the gross margin held because serving one more user cost almost nothing.
AI features sever that alignment. Inference calls, background agents, and async pipelines generate cost and value without a user present, and the cost per account now varies by an order of magnitude depending on how heavily the account uses the AI.
A user clicks one button to "analyze this account," and behind that single action the system runs a retrieval step, a planning step, a dozen tool calls, and a synthesis pass, forty inference calls billed by your provider against one seat you priced at a flat rate. The architectural reality of how AI work executes no longer maps to the unit you are selling.
What a Seat Actually Represents When an Agent Is Doing the Work
A seat is a user account: a login, a named human, an entitlement to access the product. The entire model rests on the assumption that the human is the unit of value, because the human is the one doing the work that the product makes more efficient.
An agent breaks that assumption by doing the work without the human. A scheduled job summarizes every document that landed overnight. A background process monitors a data feed and acts on it. An autonomous pipeline step runs as part of a workflow no one is watching.
One seat can now generate the value that previously required ten humans, and the seat-based model has no mechanism to capture it, because it was counting logins and the value stopped being tied to logins. This is a product architecture question before it is a contracts question, because the mismatch originates in how the software executes work, not in how the agreement is written.
The Hidden Cost Problem: When Seat Pricing Misfires on AI Workloads
Seat pricing on AI workloads fails in both directions, and both are expensive.
Undercharging happens when a power user's AI activity delivers ten times the value of a standard seat at the same price. The account runs agents continuously, triggers thousands of inference calls a month, and extracts enormous value, while paying the same flat fee as a user who logs in twice a week. You are subsidizing your heaviest users, and your provider bill climbs while your revenue stays flat. The margin collapses quietly, account by account, with no single event to flag it.
Overcharging happens at the other end. A low-usage customer pays the same seat fee as a heavy user, runs the math on what they actually get out of the product, and finds the ROI does not close. They churn, not because the product failed, but because the price was set for a usage level they never reached. The result in both directions is the same: pricing that erodes product-market fit from underneath a product that otherwise works, because the unit you charge for stopped describing the value you deliver.
Understanding Usage-Based Pricing for AI Features
Usage-based pricing charges for consumption: tokens, model calls, inference runs, or tasks completed. If you are building on top of a token-billed API like OpenAI or Anthropic, you already have a consumption-based cost structure underneath you, and the decision is whether to pass that model through to your customers or abstract it into a different unit. Passing it through directly (billing customers per token) aligns your price with your cost perfectly but exposes customers to a metric they find hard to reason about.
Abstracting it (billing per task, per document, per completed workflow) hides the token mechanics behind a unit the customer understands, at the cost of taking on the margin risk between your abstracted price and your actual token spend.
The Core Metrics That Drive AI Usage Billing
Five billing metrics matter most, and each is the right anchor under different conditions.
Compute tokens measure raw input and output volume to the model. This is the right anchor when your cost is dominated by token spend and your customers are technical enough to reason about it, common in developer tools and API products.
Model calls count discrete requests regardless of size. This works when each call represents a roughly comparable unit of work and you want a simpler metric than raw tokens.
Latency tiers charge more for faster response or priority compute. This fits when you offer a real-time tier and a batch tier with materially different infrastructure costs.
Output volume measures what the system produces: documents generated, rows processed, images created. This is the right anchor when the customer's value scales with output rather than with the compute behind it.
Task completion charges per finished unit of work: a resolved ticket, a completed enrichment, a processed invoice. This aligns price most directly with customer value, and it carries the most margin risk because the token cost per task varies.
Why Usage Pricing Rewards Efficiency and Punishes Waste
Usage pricing creates a feedback loop that changes how the team builds. When a wasteful AI call costs real money that shows up on a customer's bill, the team has a direct incentive to optimize prompts, cache repeated results, select smaller models for simpler tasks, and orchestrate calls efficiently. The pricing model enforces engineering discipline, because inefficiency is no longer invisible overhead, it is a line item the customer sees.
This is a reason to prefer usage pricing that goes beyond revenue capture. A team billing by consumption builds a leaner product, because every unnecessary inference call is a cost it is motivated to remove. A team billing by seat has no such signal, and wasteful AI calls accumulate as margin erosion that no one is incentivized to hunt down until the provider bill forces the conversation. The pricing model shapes the engineering culture, and usage pricing shapes it toward efficiency.
Seat Pricing in an AI World: When It Still Makes Sense
Seat pricing is not obsolete, and choosing it deliberately is sometimes the correct call. It holds cleanly when AI usage per seat is predictable and user-initiated, when the workflow is a tight human-in-the-loop loop where each AI action is triggered by a human and bounded by their pace, or when the buyer segment values contract simplicity over billing precision enough to accept the margin trade.
A product where every AI feature runs inside an active user session, at a pace the human sets, has predictable per-seat consumption, and the seat model fits it without the instrumentation overhead usage billing requires.
The architectures that fit the seat model cleanly share a trait: the human is still the rate limiter. As long as AI work cannot outrun the user who initiated it, per-seat consumption stays bounded, and the seat price can be set to cover it.
When the Buyer's Preference Overrides the Vendor's Cost Structure
Sometimes the economically correct model loses to what the buyer will sign. An enterprise anchor customer, the kind a seed-stage startup needs to close to make its next raise, may insist on seat pricing for reasons that have nothing to do with value alignment. Their procurement process is built around per-seat budgets, their finance team wants a predictable annual number, and a usage-based contract reads as an uncapped liability they cannot approve.
The startup then faces a real trade-off, not a failure mode. It can offer seat pricing and absorb the usage mismatch in its own infrastructure, eating the margin variance to close the deal. Or it can negotiate a custom contract with a usage component structured to survive procurement, which costs time and sales cycles the startup may not have. Offering seat pricing to land a logo you need is a legitimate strategic choice, as long as you have modeled the heavy-user tail and know what mismatch you are absorbing.
Hybrid Models: Where Seat and Usage Pricing Converge
The hybrid charges a base seat fee for access plus a usage component for AI consumption above a threshold. It trades the simplicity of pure seat pricing for fairness across usage levels, and it trades the revenue ceiling of pure seat pricing for some conversion friction at the point where customers see a variable line item.
The threshold is where the design lives: set a base allocation of, say, 1,000 task-completions per seat per month included in the seat fee, and bill overage above it.
From the customer's side, the billing experience depends entirely on where that threshold sits relative to their usage. A customer who stays under the allocation sees a clean, predictable seat charge. A customer who runs over sees the base fee plus an overage line, which feels fair if the threshold was generous and feels like a bait-and-switch if it was set low enough that most customers breach it. The threshold placement determines whether the model reads as seat pricing with a safety valve or as usage pricing wearing a seat-price headline.
The Decision Framework for Technical Founders and Eng Managers
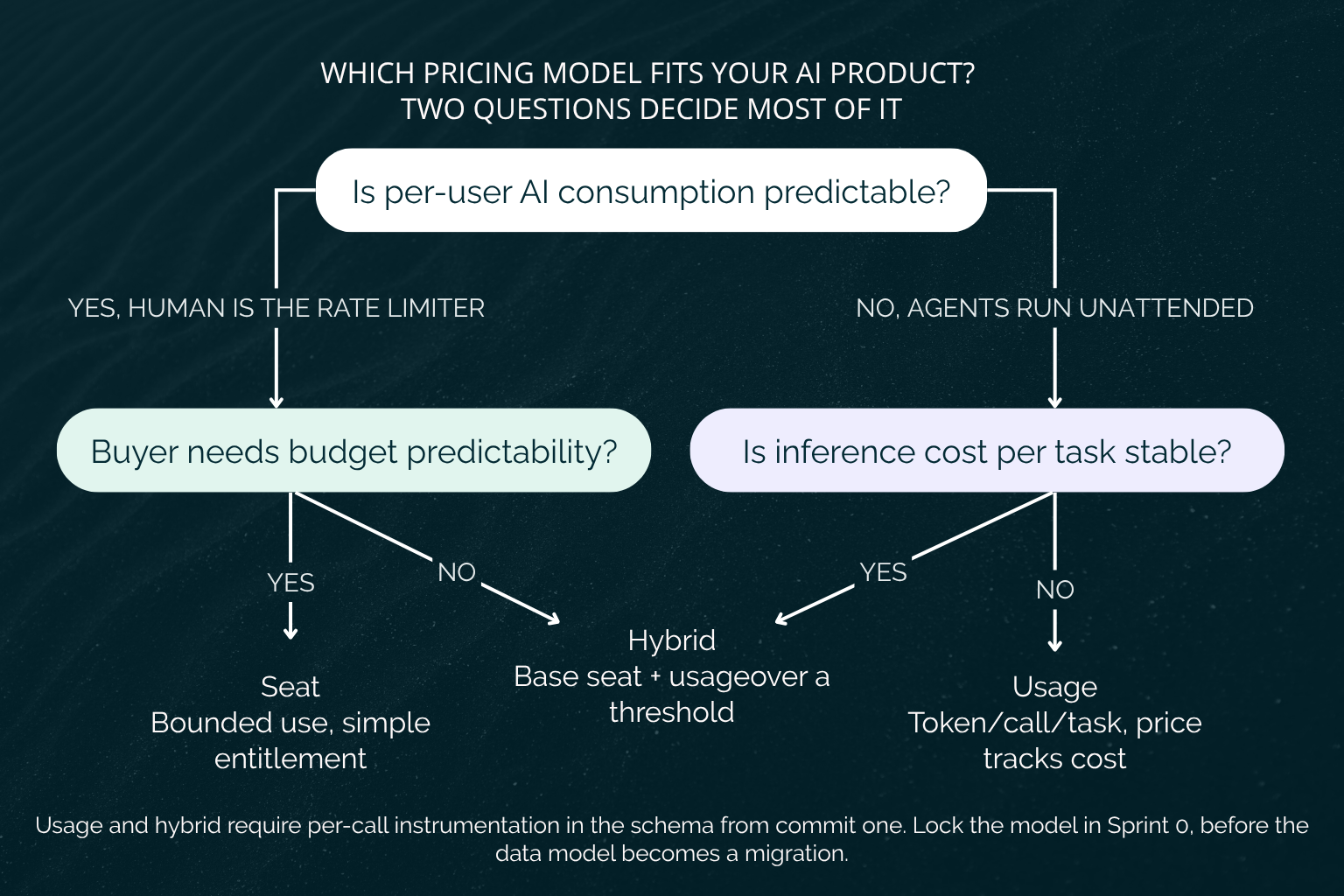
Five variables resolve the choice. Work through them against your own product and the answer usually falls out.
Predictability of per-user AI consumption. If consumption per user is tight and bounded, seat pricing can hold. If it varies by 10x across your user base, usage or hybrid is the honest model.
Variability of underlying inference cost. If your cost per task is stable, you can abstract it into a fixed unit safely. If it swings with document complexity or model selection, passing usage through protects your margin.
Buyer segment now versus in 12 months. If you sell to developers today but plan to move upmarket to enterprise next year, weigh the procurement preferences of the segment you are growing into, not just the one you have.
Product stage. Pre-launch, you are choosing a model on modeled estimates. At early traction, you have real usage data to validate it. At growth, changing the model gets expensive, which raises the cost of having chosen wrong.
What competitors have landed on and why. The category has often already stress-tested the options. Understanding why a comparable company runs usage, seat, or hybrid tells you what the buyers in your market will accept.
How the Pricing Model Shapes Product Architecture
The pricing decision has upstream build implications that make it a Sprint 0 decision rather than a go-to-market afterthought. Usage pricing requires instrumentation at every AI call from day one: token logging, customer-account association on every request, and a real-time billing pipeline that rolls raw usage into invoiceable records. None of that can be added cleanly after the fact, because the data model has to carry customer identity through every inference call.
Seat pricing allows simpler entitlement logic, a customer either has access or does not, but it creates a cost-attribution blind spot that is expensive to close later. If you bill by seat and never instrument per-account consumption, you cannot answer which customers are eroding your margin until you build the instrumentation you skipped. At Leanware, the pricing model is locked before the first build sprint precisely because the data model depends on it: how customer IDs attach to AI calls is a schema decision, and schema decisions made late are migrations, not edits.
What the Pricing Model Signals to Investors and Enterprise Buyers
The pricing model is read as a signal of maturity by two audiences who matter. A well-defined usage model tells an investor that the team understands its cost structure and has a path to gross-margin improvement as usage scales and efficiency work compounds. It says the team has found its value metric and built the instrumentation to bill on it.
A seat model with no usage component on an AI-heavy product can signal the opposite: that the team is avoiding the instrumentation work, or has not yet identified the value metric, or has not connected its provider cost to its revenue model. A founder preparing for a Series A or walking into an enterprise sales cycle should expect the pricing model to be read this way, because both a sophisticated investor and a sophisticated enterprise buyer treat it as evidence of how well the team understands its own economics.
What the Market Is Showing
The leading AI companies have stress-tested these models publicly, and the patterns are transferable. Token-based usage pricing has held where the buyer is technical and the cost structure is transparent: the foundation-model APIs from OpenAI and Anthropic bill by token because their developer buyers reason fluently in tokens and expect price to track consumption.
Seat pricing has persisted in enterprise application SKUs where the buyer wants predictability: GitHub Copilot sells per-seat to organizations because the procurement motion and the bounded per-developer usage both fit the seat model.
Hybrid models have grown as the pragmatic middle for application-layer products serving mixed buyer segments, where a base fee provides the predictability enterprise wants and a usage component captures the upside from heavy accounts.
The transferable lesson is that the model follows the buyer and the cost structure together. Technical buyers with transparent costs tolerate usage pricing; enterprise buyers with bounded usage prefer seats; mixed segments with variable usage land on hybrid. Locate your product on those two axes and the market has already shown you where you are likely to end up.
What Pricing Decisions Mean During Sprint 0
Pricing decisions often appear to be commercial decisions that can be finalized later in the product lifecycle. For AI products, they also have technical implications. Usage-based and hybrid models require instrumentation, usage tracking, and cost attribution mechanisms that need to be considered early in the architecture.
When those requirements are not identified during planning, teams may discover later that they lack the data needed to understand customer-level consumption, monitor margins, or support usage-based billing. Adding that visibility after launch is usually more expensive than designing for it from the start because the underlying data model and event tracking architecture may need to be revisited.
This is one reason pricing discussions are valuable during Sprint 0. The goal is not simply to choose how customers will be charged, but to ensure the product architecture can support that model as the product scales.
Choosing the Right Pricing Model Before You Build the Wrong Infrastructure
The pricing model is a product architecture decision, not a billing decision, and it has to be made before the build begins because the data model depends on it. The three options, seat, usage, and hybrid, map to different instrumentation requirements, and the five-variable framework (consumption predictability, cost variability, buyer segment trajectory, product stage, and competitive landscape) resolves which one fits. As autonomous agents take on more work that no human initiates, the set of products where the seat model fits cleanly keeps shrinking, because the seat model depends on the human staying the rate limiter, and agents are removing the human from the loop.
Sprint 0 is the right moment to lock this decision, because it happens before the first build sprint, while the schema is still a design rather than a migration. Start with Sprint 0 to resolve the pricing model before it gets encoded into infrastructure that is expensive to change.
Frequently Asked Questions
How do I estimate AI cost variability before my product is live?
You cannot measure actual usage pre-launch, but you can model it from first principles. Identify the AI calls each core user action triggers, assign a token estimate to each call using your provider's pricing calculator, and model three user archetypes, light, median, and heavy, against your projected seat counts. The output is not a precise forecast; it is a range. If the range between your light and heavy archetypes is wide enough that flat per-seat pricing would either bankrupt your margin on heavy users or overprice light ones, that is your signal that usage or hybrid billing is necessary. Stress-test this model during Sprint 0 before you commit the billing architecture to code, because the model's conclusion determines the schema.
What instrumentation does usage billing actually require, and how long does it take to build?
At minimum: an event emitter at every AI call that logs the model used, the token count, and the customer ID; an aggregation layer that rolls those events into billing-period totals; an integration with a billing provider like Stripe Billing or Lago that translates usage records into invoice line items; and a customer-facing usage dashboard so buyers are not surprised at month-end. On a greenfield, reasonably simple product, that is two to four weeks of focused engineering. The reason to build it during Sprint 0 rather than after launch is that the data model, specifically how customer IDs attach to every AI call, has to be in the core schema from the first commit. Bolting it on later means migrating a live system, which costs far more than the original two to four weeks.
A customer is refusing usage-based pricing and insisting on a flat seat fee. What do we do?
You have three concrete options. Set the seat price at the 80th-percentile usage cost for that customer's segment, so the seat absorbs the variance and the customer gets the predictability they want. Or offer a seat price with a usage cap, above which overage billing kicks in, giving the customer a predictable baseline while you capture upside from heavy use. Or model the customer's expected usage before the contract signs, set the seat price to fit it, and revisit at renewal. The mistake to avoid is accepting a seat price set to median usage without modeling the heavy-user tail, because that is exactly where margin collapses when the customer turns out to be a power user.
Does a hybrid model create more conversion friction than it solves?
It depends on where you set the threshold. A hybrid with a low base allocation, where usage billing kicks in after a small included amount, reads as usage pricing with a misleading seat-price headline; customers feel ambushed at month-end and churn follows. A hybrid with a generous allocation, where the base covers typical use for roughly 80% of customers, reads as seat pricing with a safety valve for power users and converts cleanly. The rule of thumb: if most customers never reach the overage tier, the model lands as seat pricing in practice and you should present it that way. If a significant share hits overage regularly, the hybrid is functioning as usage pricing, and you should communicate it as usage pricing from the first conversation rather than letting the bill reveal it.
At what point does the pricing model become hard to change without breaking customer contracts?
The inflection point is your first enterprise contract with a multi-year term and a fixed seat price. Before that contract exists, pricing changes are operationally disruptive but manageable: you grandfather existing customers or migrate them with notice. After it exists, changing the model means either honoring that contract through its full term, which forces you to run two billing systems in parallel, or renegotiating, which spends real relationship capital. The practical implication is that the pricing model should be treated as locked at the point of your first enterprise contract, not at launch, which is why Sprint 0, before the first sales cycle closes, is the correct moment to make the decision deliberately rather than discovering it later.