AI Feature Pricing Models: Usage-Based vs. Seat-Based: How to Choose
Most teams treat pricing as a billing decision they can settle close to launch. For an AI product, that is exactly how the wrong model gets locked in.
Choosing between seat-based and usage-based ai pricing models shapes more than the pricing page. It affects what the product instruments, what the schema needs to carry, how costs are attributed, and what the team can credibly tell investors about unit economics. Once the build is underway, those decisions become harder and more expensive to change.
For founders building AI-native or AI-augmented products, the pricing model has to be decided before the architecture sets. Not after the first enterprise customer pushes back on the contract. Not after usage patterns start breaking the margins. Before the first version ships, the team needs to know what unit of value the product delivers and whether a seat, a usage metric, or a hybrid model is the cleanest way to price it.
How AI Is Breaking the Seat-Based Pricing Assumption
Seat-based pricing was the SaaS default for good reasons. It maps cleanly to user accounts, it tracks headcount the way enterprise procurement already budgets, and it produces a predictable annual number that a finance team can approve without modeling usage. For a product where each user does roughly comparable work in a session, the seat is a clean proxy for value, and the model holds.
AI features break the proxy the moment agents, background automation, or asynchronous inference enter the product. The value an account generates stops tracking the human attached to it. A single user triggers forty inference calls in one session by clicking a button that fans out into retrieval, planning, and synthesis steps. A pipeline runs overnight with no user present at all, processing a queue that accumulated while everyone was asleep.
The cost you pay your model provider scales with that activity while the price you charge scales with seats, and the two curves diverge. This is an architectural mismatch, not a pricing philosophy disagreement, because the work no longer executes in a way the seat can measure.
What "Per Seat" Actually Means When an Agent Is Doing the Work
In traditional SaaS, a seat is a named user: a login, a license, a human with an account. The model assumes that human is the unit of value, because the human is doing the work the product accelerates, and the cost to serve them is low and stable.
An agent severs that assumption by generating and consuming value across sessions and pipelines with no human in the loop. Consider a document-processing agent that runs 200 jobs a day for a single-seat user. Under seat pricing, that account pays the same as a single-seat user who runs two jobs a week, while consuming a hundred times the inference. The ambiguity is not theoretical.
It shows up the first time the billing model meets a real usage pattern, and a founder building an AI-native product needs to see it coming before the product ships, because by then the seat price is published and the heavy accounts are already unprofitable.
The Hidden Cost Problem: When Seat Pricing Misfires on AI Workloads
Seat pricing on AI workloads misfires in two directions, and for a startup in early growth, both quietly cost you.
Undercharging is the first. A power user runs agents non-stop, pulls enormous value, and pays the same flat fee as a casual user. They know they are getting a steal, so they never upgrade, and your expansion revenue flatlines exactly where it should be climbing, all while your provider bill keeps rising against that flat fee.
Overcharging is the other. A light user pays the same flat rate as a power user, does the ROI math on what they actually touch, and it does not add up. They leave, not because the product was bad, but because the price was set for a usage level they never came close to. A model that is totally fine for conventional SaaS turns into a churn problem on one end and a stalled-expansion problem on the other, the moment your customers' usage starts ranging over 10x.
Here is the misfire in one view:
Customer type | What they consume | What they pay (flat seat) | What happens |
Power user | 10x the inference | Same as everyone | Gets a deal, never upgrades, erodes margin |
Median user | About what you priced for | Same as everyone | Model works fine here |
Light user | A fraction of the value | Same as everyone | ROI doesn't close, churns |
Understanding Usage-Based Pricing for AI Features
Usage-based pricing charges for what the product consumes or produces: tokens, API calls, inference runs, tasks completed, documents processed. It aligns revenue with the value the product actually delivers, because the customer who gets more out of the product pays more, and the customer who gets less pays less. The alignment is the appeal, and the cost of achieving it is engineering work.
Usage billing requires instrumentation from day one. Every AI call has to log who triggered it, what it consumed, and when, and that data has to roll up into something a billing system can invoice. That instrumentation is real engineering cost, and it is also a feedback loop: a team that meters every call to bill for it also gets, for free, a precise view of how the product is actually used in production, which is information seat-priced teams usually lack.
The Core Metrics That Drive AI Usage Billing
Four billing units cover most AI products. Each maps to a different way customers feel value.
Billing unit | What it measures | When it fits |
Compute tokens | Raw input/output volume to the model | LLM products where token spend dominates and buyers are technical |
Model calls | Discrete requests, regardless of size | When latency tiers matter and you want a simpler unit than tokens |
Output volume | What the system produces (docs, summaries, generations) | When value lives in finished outputs, not the compute behind them |
Task completion | A finished unit of work (resolved ticket, processed invoice) | Agent products where the unit of value is a completed workflow |
Task completion aligns price with value the most directly, and it carries the most margin risk, because the compute cost per task swings with the work. Pick the unit that matches how your customer experiences value, because that is the one they will accept seeing on an invoice without arguing..
Why Usage Pricing Rewards Efficiency and Punishes Waste
Usage pricing creates an engineering feedback loop that compounds into a unit-economics advantage. When every token and every call carries a cost the customer sees, the team optimizes by reflex: it structures prompts tightly, caches repeated results, selects the right model for each task rather than defaulting to the largest one, and cuts redundant inference. Inefficiency stops being invisible overhead and becomes a cost the team is motivated to remove.
For a seed-to-Series-A startup, building those optimization instincts early is a competitive advantage, because the discipline is hard to retrofit later. A team that priced by seat and never had to count tokens accumulates wasteful patterns that become load-bearing, and unwinding them after the product scales is far more expensive than building lean from the start.
The pricing model shapes the engineering culture, and usage pricing shapes it toward the efficiency that protects margin as the product grows.
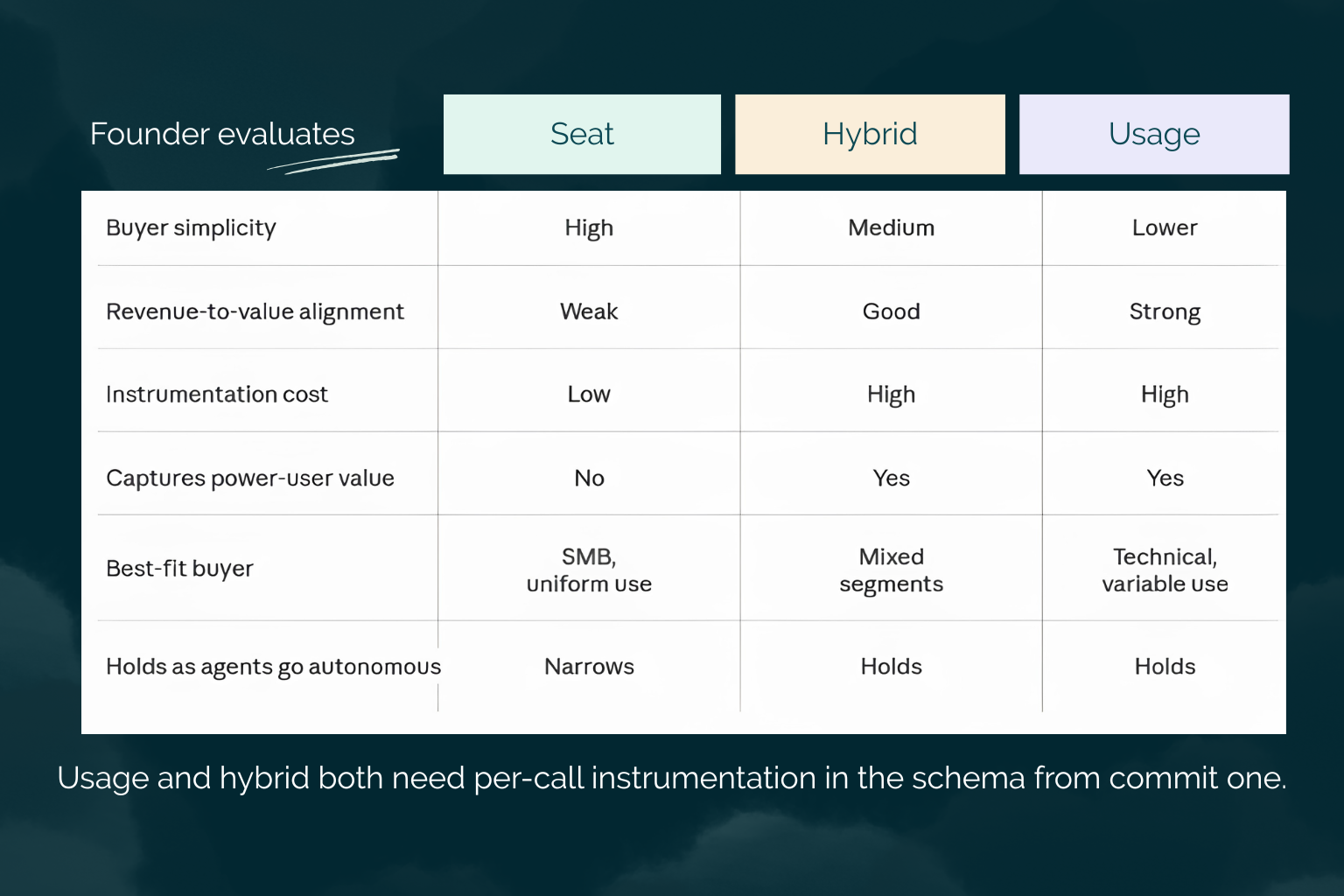
Seat Pricing in an AI World: When It Still Makes Sense
Seat pricing is still the right call under real conditions, and choosing it deliberately is not a compromise. It holds when user behavior is predictable, when AI usage per seat is relatively uniform across the customer base, and when the buyer values contract simplicity enough to accept the trade in pricing precision. For a startup, the forward-looking version of this argument matters most: if your downstream customers are SMBs or mid-market teams with lightweight procurement and a familiar headcount anchor, seat pricing can reduce friction at the point of sale even when it is not the most economically precise model.
The trade is genuine. You give up some pricing accuracy and accept some margin variance, and in return you get a pricing page a buyer understands instantly and a contract that closes without a usage-modeling conversation. For the right buyer segment, that friction reduction is worth more than the precision you give up.
When Uniform Usage Makes Seat Pricing the Right Call
Per-seat pricing fits cleanly when the AI feature is genuinely tied to one user's workflow. A personal writing assistant, a per-developer code-suggestion tool, an individual research aid, each of these has AI usage bounded by a single human's pace, and usage variance across seats stays low enough that flat pricing is a reasonable approximation rather than a margin gamble.
When every seat uses the AI feature at roughly the same intensity, the instrumentation overhead of usage billing can cost more than the pricing precision it would buy.
The test is variance. If your heaviest seat and your lightest seat consume within a small multiple of each other, seat pricing approximates value well, and the engineering cost of metering is not worth paying. If they diverge by 10x, the approximation breaks and the flat seat starts subsidizing the heavy users out of the light ones.
Hybrid Models: Where Seat and Usage Pricing Converge
The hybrid charges a base seat fee for access plus a usage component for consumption above a threshold, and it is a deliberate trade between conversion simplicity and revenue accuracy. The base seat fee lowers onboarding friction because the buyer knows what they are committing to. The usage overage captures the value delivered to high-intensity users without penalizing the light ones who stay under the threshold. The threshold is the design decision: set a generous base allocation, and most customers experience clean seat pricing while power users pay for the upside they extract.
This pattern is increasingly what buyers expect when they open an AI product's pricing page, because the market has trained them to see a base tier with usage-based expansion above it. A hybrid framed clearly (here is what is included, here is what heavy use beyond it costs) reads as fair and converts well. The risk lives entirely in where the threshold sits and how clearly it is communicated, which the FAQ below addresses directly.
The Strategic Decision Framework for Founders and Engineering Leaders
Five questions resolve the choice for a specific product. Work through them during the build, not after.
How predictable is user behavior across your target segment? Tight, bounded usage supports seat pricing. Usage that varies by an order of magnitude calls for usage or hybrid.
How variable are AI costs per user session? Stable per-session cost can be abstracted into a flat unit safely. Cost that swings with task complexity or model selection is safer to pass through as usage.
Which segment does the product target? SMB buyers often prefer simple seat pricing; enterprise buyers want predictability but can absorb usage with the right controls; a product moving upmarket should weigh the segment it is growing into.
What stage is the product at? Pre-launch, you choose on modeled estimates. In growth, you have real usage data, and changing the model later gets costly, which raises the price of choosing wrong now.
What are competitors signaling on their pricing pages? The category has often already tested what its buyers accept, and a comparable company's model tells you what your shared buyers will tolerate.
Mapping Pricing Model to Product Architecture
The pricing decision has direct upstream consequences for how the AI features get built. Usage pricing requires instrumentation at every AI call: token counting, call logging, and cost attribution tied to a customer identity, all of which is engineering work that has to be scoped into the build rather than added later. Seat pricing allows simpler entitlement logic, access or no access, but it leaves a cost-attribution blind spot, because a seat-priced product that never meters consumption cannot tell you which customers are eroding margin until you build the metering you skipped.
For a startup going through Sprint 0, this belongs in the scope conversation, not in a post-launch retrofit. Teams that defer the instrumentation decision to "after we launch" consistently pay more to add it later, because the data model, specifically how a customer ID attaches to every AI call, has to live in the core schema from the first commit. Adding it afterward is a migration through a live system, not an edit.
How to Signal Pricing Model Confidence to Investors and Buyers
The pricing model communicates product maturity to people who matter outside the building. A well-defined usage model tells a Series A investor that the team understands its cost structure and can model unit economics as the product scales, which is a real diligence signal rather than a presentation flourish. It says the team found its value metric and built the instrumentation to bill on it.
A seat model with no usage component on an AI-heavy product can signal the opposite: that the team has not instrumented the product well enough to know its cost per customer, or has not yet found the value metric. For a CTO or CPO preparing for a funding round or a first enterprise sales cycle, the pricing model is part of the product story, because both a sophisticated investor and a sophisticated enterprise buyer read it as evidence of how well the team understands its own economics.
AI Pricing Models in Practice: What the Market Is Showing
The leading AI companies have made this decision publicly, and their choices are informative as long as you read them as context-specific rather than universal.
OpenAI and Anthropic both price on tokens, because their buyers are technical, their costs are transparent, and consumption is the honest unit. GitHub Copilot uses seat-based pricing because the unit of value maps cleanly to a developer's daily workflow and the per-developer usage stays bounded enough for a flat seat to work. Newer AI-native SaaS products are experimenting with hybrid models to reduce enterprise friction while still capturing power-user value.
The lesson for a founder is that each of these models reflects a specific distribution motion and buyer, and none of them automatically transfers to a product with a different buyer and a different usage pattern. The foundation-model APIs price the way they do because they sell to developers who reason in tokens. Copilot prices the way it does because it sells seats to organizations with predictable per-developer use. Your model should follow your buyer and your cost structure, not the logo you most admire.
What Leanware's Sprint 0 Work Surfaces About Pricing Architecture
Across AI-native and AI-augmented builds we run through Sprint 0 and milestone-billed engagements, the same thing happens almost every time: pricing architecture is rarely on the table before Sprint 0, and it almost always surfaces during it. The reason is structural. To scope an AI feature properly you have to name the unit of value it delivers, and that is the exact question the pricing model has to answer. They are the same conversation, and you cannot really scope the build without having it.
Founders who walk in without a view on pricing walk out with one, and it changes what gets built, because it decides whether per-call instrumentation is in scope from sprint one. Defer it and the instrumentation does not get built, the schema does not carry per-account usage, and you pay later to retrofit it under production load. Naming the unit of value early is not a commercial nicety here. It is the difference between instrumenting from the first commit and migrating a live billing system after launch.
Final Thoughts
The pricing model is a product architecture decision wearing a billing question's clothes. It has to be made before the build locks, and the right answer comes from your user behavior, your customer segment, and what the product actually delivers, not from whatever model is trending this quarter. Seat, usage, and hybrid each fit specific conditions, and the five questions above tell you which conditions you are in. And as agents take on more work that no user kicks off, the unit of value keeps drifting away from individual user actions, which means the set of products where a flat seat fits cleanly keeps getting smaller.
If you are working through this during a build, bring it into a Sprint 0 conversation, because that is where scope, architecture, and pricing get resolved together instead of one after another.
Frequently Asked Questions
If I go usage-based, how do I stop customers from getting a surprise bill at the end of the month?
A surprise bill is a customer-experience problem, not a reason to bail on usage pricing. The fix is spend controls in the product: soft caps that warn as someone nears a limit, a live spend dashboard, and threshold alerts that fire before the bill becomes a shock. The infra providers underneath you, OpenAI, Anthropic, AWS Bedrock, all expose hard and soft limit tooling at the API level, so pass equivalent controls through to your own customers rather than retreating to seat pricing to dodge the problem.
How much engineering work does it actually take to instrument usage billing correctly?
Real work, but knowable. The data layer is the floor: every AI call logs a user or session ID, a token or cost count, and a timestamp. The integration layer rolls those events into billing-ready records and wires them to a metering system like Stripe Billing, Orb, or Lago, which is usually one to three weeks of focused effort on a reasonably simple product. The expensive part is not the metering integration, it is making sure customer identity rides on every AI call from the first commit, because that is the piece that hurts to add after launch.
My product sells to both SMBs and mid-market buyers. Can I run one pricing model for both, or do I need two?
Most teams try one model and end up with a pricing page that satisfies neither. The practical move is to build around the segment that drives your most near-term revenue, match it to how those buyers actually buy, and treat the other segment as a future-state expansion that might earn its own tier later. Forcing one model to fit a light SMB procurement motion and a heavier mid-market buyer at once usually lands on a compromise that converts badly on both sides.
Won't a hybrid model (seat base + usage overage) just confuse buyers at the point of sale?
It can, but the confusion almost always comes from the explanation, not the model. "You get X included, and heavy usage beyond that is billed at Y per unit" is clear to most buyers and converts fine. The version that loses deals is the one that makes a buyer open a calculator to guess their own monthly bill. If the included allocation covers typical use for most customers, it reads as seat pricing with a safety valve and lands cleanly. Clear framing carries it.
How do I talk about the pricing model in a Series A pitch without it reading as unresolved?
The investor is really asking whether you understand your unit economics: cost per customer, revenue per customer, and where those two lines head as you scale. A usage-based model with real cost-per-inference numbers and measured usage patterns answers that directly and signals you instrumented the product properly. Framed that way, the pricing model reads as evidence of maturity, not an open question, because you are showing the cost structure and the value metric together instead of describing a billing scheme you have not grounded in data yet.